About
Natural Language Processing (NLP) methods are increasingly being used to mine knowledge from unstructured health texts. Recent advances in health text processing techniques are encouraging researchers and medical domain experts to go beyond just reading the information included in published texts (e.g. academic manuscripts, clinical reports, etc.) and structured questionnaires, to discover new knowledge by mining health contents. This has allowed other perspectives to surface that were not previously available.
Over the years many eHealth challenges have taken place, which have attempted to identify, classify, extract and link knowledge, such as Semevals, CLEF campaigns and others [1].
Inspired by previous NLP shared tasks like “ Semeval-2017 Task 10: ScienceIE [1] ” and research lines like Teleologies [2], both not specifically focussed on the health area, eHealth-KD proposes modelling the human language in a scenario in which Spanish electronic health documents could be machine readable from a semantic point of view. With this task, we expect to encourage the development of software technologies to automatically extract a large variety of knowledge from eHealth documents written in the Spanish Language.
The documents used as corpus have been taken from MedlinePlus and manually processed to make them fit for the task. Additional details are provided at the end of this document.
Tasks
To achieve this purpose, three subtasks are presented:
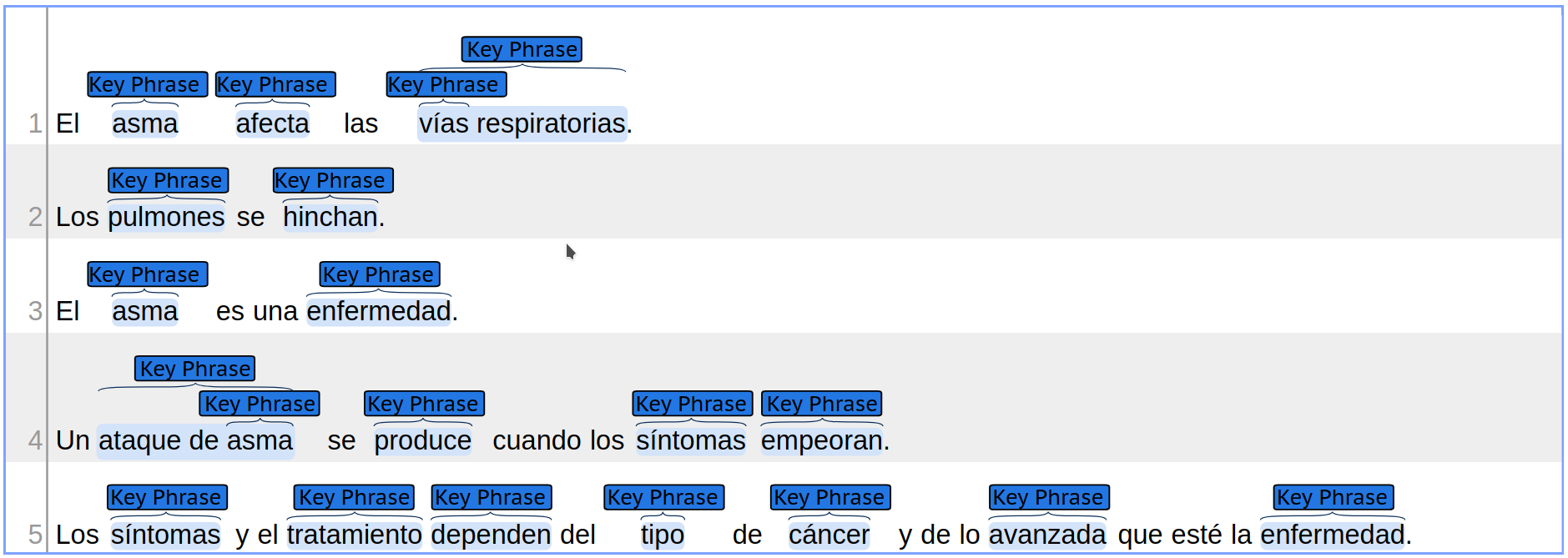
Subtask A: Identification of key phrases
Given a list of eHealth documents written in Spanish, the goal of this subtask is to identify all the key phrases per document.
Read further details for Subtask A.
Example input document:
Visual representation of the output:
Example output document:
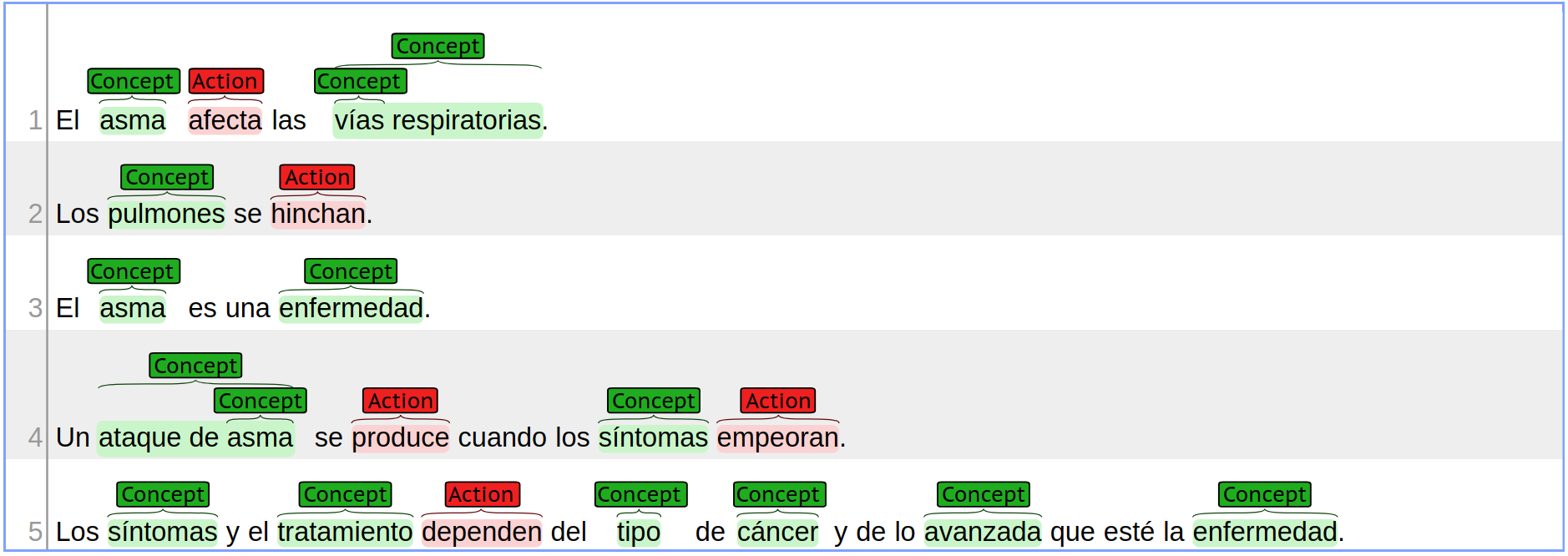
Subtask B: Classification of key phrases
Subtask B continues where Subtask A ends. Given an input file in plain text and the corresponding output from Subtask A, where the text spans that appear in the input have been identified, the purpose of Subtask B is to assign a label to each of these text spans.
Read further details for Subtask B.
Visual representation of the output:
Example output document:
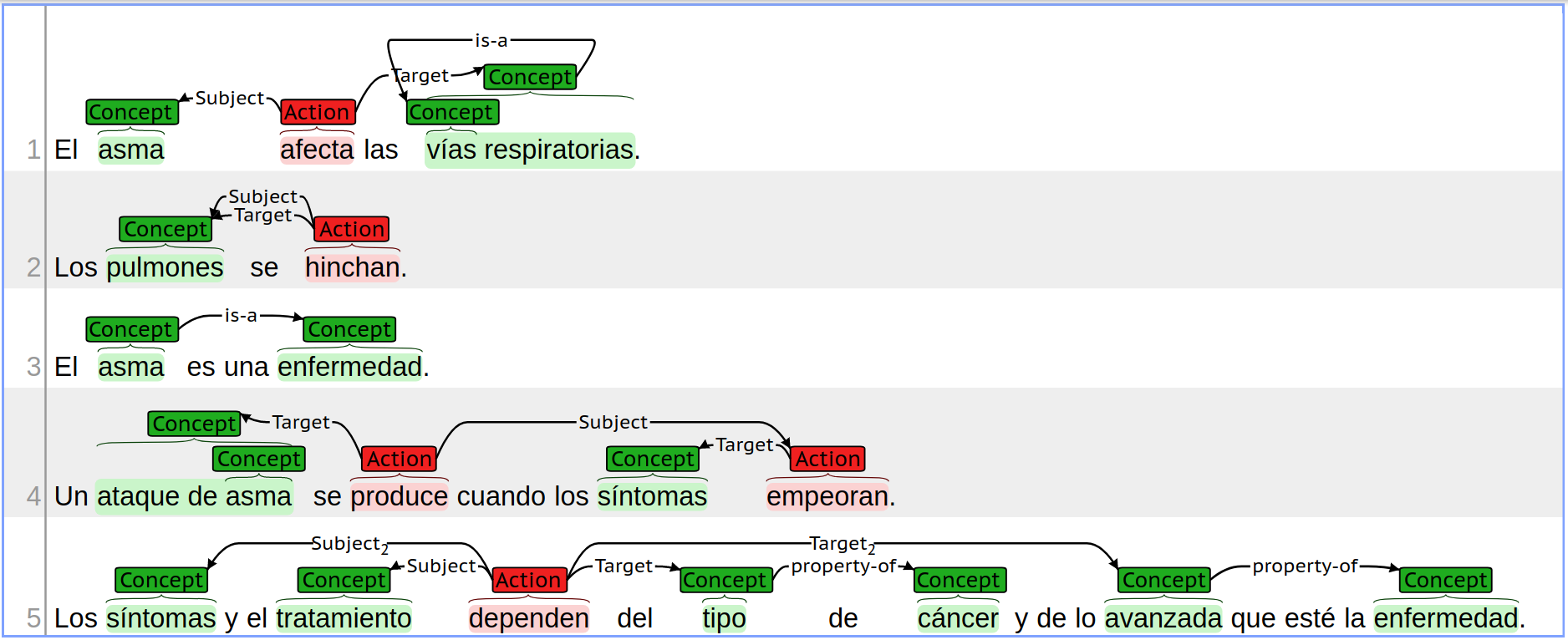
Subtask C: Setting semantic relationships
Subtask C continues from the output of Subtask B, by linking the entities detected and labelled in each document. Given an input file (i.e. input_<topic>.txt ) and the outputs from both Subtasks A and B, the purpose of this Subtask is to recognize all relevant semantic relationships between the entities recognized. The semantic relationships found in the gold example of the previous sections are illustrated in the following figure:
Read further details for Subtask C.
Visual representation of the output:
Example output document:
Competition results
We are pleased to inform that the TASS-2018 Task 3 competition has finished! The following tables show the overall results and some additional metrics. Congratulations to all participants!
All participants are encouraged to submit a description of their system to the competition organizers, in order to appear in the competition memories, and additionally a paper describing their system to the TASS 2018 Workshop. More details are given in Publication instructions section.
Further details can be seen in the TASS-18 Task3 Final Results spreadsheet.
Best overall results:
| First place | rriveraz | F1 = 0.464 | <- Winner |
|---|---|---|---|
| Second place | plubeda | F1 = 0.461 | |
| Third place | upf_upc | F1 = 0.446 |
Best results per scenario
| Best scenario 1 | rriveraz | F1 = 0.744 |
| Best scenario 2 | TALP | F1 = 0.722 |
| Best scenario 3 | TALP | F1 = 0.448 |
Best results per task
| Best Task A | rriveraz | F1 = 0.872 |
| Best Task B | rriveraz | Acc = 0.959 |
| Best Task C | TALP | F1 = 0.448 |
General results for all participants:
| Name | plubeda | rriveraz | upf_upc | TALP | VSP | baseline | Marcelo |
|---|---|---|---|---|---|---|---|
| S1 Micro F1 | 0.71 | 0.744 | 0.681 | N/A* | 0.297 | 0.566 | 0.181 |
| S2 Micro F1 | 0.674 | 0.648 | 0.622 | 0.722 | 0.275 | 0.577 | 0.255 |
| S3 Micro F1 | N/A* | N/A* | 0.036 | 0.448 | 0.42 | 0.107 | 0.018 |
| Average F1 | 0.461 | 0.464 | 0.446 | 0.39 | 0.331 | 0.417 | 0.151 |
N/A*: Not Available. The corresponding participant did not submit for a given scenario. In the overall ranking it is counted as if obtaining zero F1 for that scenario, and averaged with the remaining scenarios.
NOTE After receiving indications that some system's output contained duplicated entries, the evaluation scripts were executed again after eliminating all duplicated lines from all participant's submissions. The next table shows the results that change taking that consideration into account. Participants are encouraged to use these complementary results and discuss them as they fit in their respective papers. However, for competition purposes, the previous results are the official ones. Results which differ from the original score are highlighted in red color.
These modified results do not alter the overal ranking of participants neither in scenarios nor individual tasks.
General results for participants that change:
| Name | upf_upc | VSP |
|---|---|---|
| S1 Micro F1 | 0.681 | 0.310 |
| S2 Micro F1 | 0.626 | 0.294 |
| S3 Micro F1 | 0.036 | 0.444 |
| Average F1 | 0.448 | 0.349 |
Corpora description
The corpora used is based on a set of Spanish health electronic documents collected from MedlinePlus. Click here to read further details about the corpora and other resources.
Overall evaluation
The evaluation is based on the standard information extraction metrics of precision and recall. Further details are provided in this link.
Instructions for participating
The competition is managed and run in the Codalab Competitions platform. For participation, please register on the platform and follow the instructions detailed there. The following pages provide a detailed description of the problem to be solved and the evaluation. In Codalab you will find details about how to submit a solution, as well as all relevant links.
Click here to enter the competition.
To download the relevant data, please visit: https://github.com/TASS18-Task3/data.
Publication instructions
Please review the official TASS 2018 proceedings publication instructions. The following instructions are subject to change to adapt to the official TASS 2018 requirements.
Send your paper to our Program Comitee at chairs_TASS2018_eHealth-KD@googlegroups.com before July 2nd, 2018.
The Organization Committee of eHealth-KD encourages participants to submit a description paper of their systems. Submitted papers will be reviewed by a scientific committee, and only accepted papers will be published at CEUR. The proceedings of eHealth-KD will be jointly published with the proceedings of all the tasks of TASS-2018. The submitted papers will be peer-reviewed by a Program Commitee which is composed by all the participants in Task 3 and the Organization Commitee.
The manuscripts must satisfy the following rules:
- Up to 6 pages plus references formatted according to the SEPLN template.
- Articles can be written in English or Spanish. The title, abstract and keywords must be written in both languages.
- The document format must be Word or Latex, but the submission must be in PDF format.
- Instead of describing the task and/or the corpus, you should focus on the description of your experiments and the analysis of your results, and include a citation to the Overview paper. Indications for this citation will be provided in due time.
Depending on the final number of participants and the time allocated for the workshop, all or a selected group of papers will be presented and discussed in the Workshop session.
Discussion group
A Google Group has been set up for this TASS “ eHealth Shared Task” where announcements will be made. Do send your questions and feedback to tass2018_ehealth-kd@googlegroups.com or visit the Google Groups page to participate in the discussion.
Contact person
Yoan Gutiérrez Vázquez ygutierrez@dlsi.ua.es
Important dates
Trial data ready
12 Feb 2018
Release of baseline implementation
11 Apr 2018
Registration deadline due by 23:59 GMT -12:00
28 May 2018
Publication of competition results
30 May 2018
Submission of system description paper's due by 23:59 GMT -12:00
02 Jul 2018
Peer-review of system paper's due
23 Jul 2018
Author notifications
31 Jul 2018
Camera ready submissions due
31 Aug 2018
Organizing Committee
Acknowledgments
This research task is partially funded by the University of Alicante, Generalitat Valenciana, Spanish Government (“Ministerio de Economía y Competitividad”) through the projects REDES (TIN2015-65136- C2-2-R) and “Plataforma inteligente para recuperación, análisis y representación de la información generada por usuarios en Internet” (GRE16-01).
Both projects have partially designed their evaluation stages over this shared task.
References
[1] Gonzalez-Hernandez, G. and Sarker, A. and O’Connor, K. and Savova, G. Capturing the Patient’s Perspective: a Review of Advances in Natural Language Processing of Health-Related Text. Yearbook of medical informatics; 26(01), p 214--227. 2017
[2] Giunchiglia, F., & Fumagalli, M. (2017, November). Teleologies: Objects, Actions and Functions. In International Conference on Conceptual Modeling (pp. 520-534). Springer, Cham.
[3] MedlinePlus [Internet]. Bethesda (MD): National Library of Medicine (US). Available from: https://medlineplus.gov/ .
Organized by:
