Tasks
Four tasks are proposed for the participants covering different aspects of sentiment analysis and automatic text classification.
Groups may participate in one or several tasks.
Task 1: Sentiment Analysis at global level
This task consists on performing an automatic sentiment analysis to determine the global polarity (using 5 levels) of each message in the test set of the General corpus.
Participants will be provided with the training set of the General corpus so that they may train and validate their models.
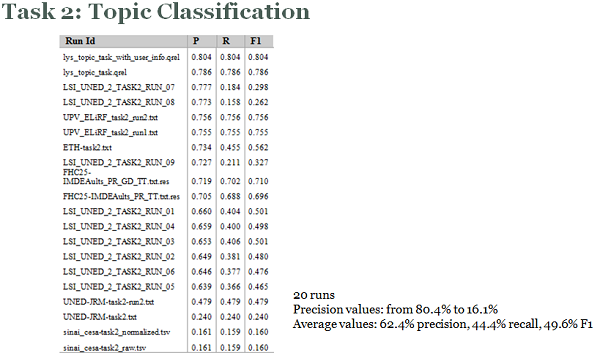
Task 2: Topic classification
The technological challenge of this task is to build a classifier to automatically identify the topic of each message in the test set of the General corpus.
Participants may use the training set of the General corpus to train and validate their models.
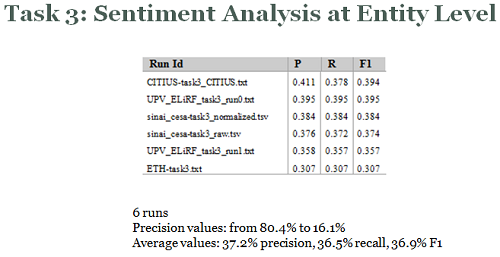
Task 3: Sentiment Analysis at entity level
This task consists on performing an automatic sentiment analysis, similar to Task 1, but determining the polarity at entity level (using 3 polarity levels) of each message in the Politics corpus.
In this case, the polarity at entity level included in the training set of the General corpus may be used by participants to train and validate the models (converting from 5 polarity levels to 3 levels).
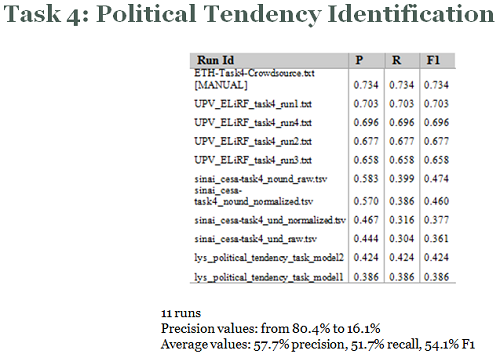
Task 4: Political tendency identification
This task moves one step forward and the objective is to estimate the political tendency of each user in the test set of the General corpus, in four possible values: LEFT, RIGHT, CENTRE and UNDEFINED.
Participants may used whatever strategy they decide, but a first approach could be to aggregate the results of the previous tasks by author and topic.
The evaluation metrics to evaluate and compare the different systems are the usual measurements of precision (1), recall (2) and F-measure (especifically F1) (3) calculated over the full test set:
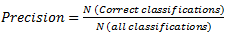 (1)
(1)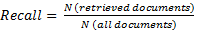 (2)
(2)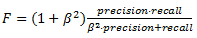 (3)
(3)Participation
Experiments
Participants are expected to submit one or several results of different experiments for one or several of these tasks, in the appropriate format.
Results for all tasks must be submitted in a plain text file with the following format:
id \t output \t confidence
where:
- id is the tweet ID for Tasks 1 and 2, the combination of tweet ID and entity for Task 3 (such as 142378325086715906-UPyD), and the user ID for Task 4
- output refers to the expected output of each task (polarity values, topic or political tendency)
- confidence is a number ranging [0, 1] that indicates the confidence in the value as assigned by the system
Regarding the polarity values, there are 6 valid tags (P+, P, NEU, N, N+ and NONE). Although the polarity level must be classified into those levels and results will be evaluated for the 5 of them, the evaluation will include metrics that consider just 3 levels (POSITIVE, NEUTRAL and NEGATIVE).
Regarding the topic classification, a given tweet ID can be repeated in different lines if it is assigned more than one topic.
Results
31 groups registered (15 groups last year) and 14 groups (9 last year) sent their submissions.
| Group | Task 1 | Task 2 | Task 3 | Task 4 |
| CITIUS-USC | 2 | - | 1 | - |
| DLSI-UA | 3 | - | - | - |
| Elhuyar | 2 | - | - | - |
| ETH-Zurich | 3 | 1 | 1 | 1 |
| FHC25-IMDEA | - | 2 | - | - |
| ITA | 1 | - | - | - |
| JRC | 18 | - | - | - |
| LYS | 2 | 2 | - | 2 |
| SINAI-EMML | 2 | - | - | - |
| SINAI-CESA | 2 | 2 | 2 | 4 |
| Tecnalia-UNED | 1 | - | - | - |
| UNED-JRM | 2 | 2 | - | - |
| UNED-LSI | 15 | 9 | - | - |
| UPV | 3 | 2 | 2 | 4 |
| Total groups | 13 | 7 | 4 | 4 |
| Total runs | 56 | 20 | 6 | 11 |
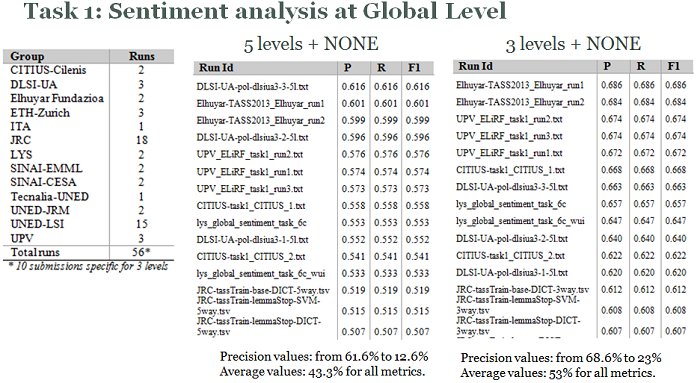
Results achieved by the best experiments in each of the four tasks, sorted by precision value, are shown in the next figures.
Detailed results can be downloaded from the links below using the provided user and password for the private area.
The Excel sheet contains the summary of results of all experiments for each task. Then specific results for each task are contained in the 5 different compressed files, which in turn store the overall results for the task and the results per experiment, the confusion matrix to allow error analysis and the gold standard for the task (qrel) itself.
A PHP script and gold standards used for the evaluation of each submission are also included for your convenience (gold standards are also in the compressed file for each task).
- tass2013-results.xlsx [28.3KB, 2019-06-28]: Results for TASS 2013 (Excel sheet)
- task1-5l.tgz [26.8MB, 2019-06-28]: Results for Task 1, 5 levels
- task1-3l.tgz [26.5MB, 2019-06-28]: Results for Task 1, 3 levels
- task2.tgz [9.9MB, 2019-06-28]: Results for Task 2
- task3.tgz [200.5KB, 2019-06-28]: Results for Task 3
- task4.tgz [11.1KB, 2019-06-28]: Results for Task 4
- tass2013-eval.php.gz [802B, 2019-06-28]: PHP script for the evaluation
- tass2013-task1-5l.qrel [1.3MB, 2019-06-28]: Goldstandard for Task 1, 5 levels
- tass2013-task1-3l.qrel [1.3MB, 2019-06-28]: Goldstandard for Task 1, 3 levels
- tass2013-task2.qrel [1.7MB, 2019-06-28]: Goldstandard for Task 2
- tass2013-task3.qrel [65.2KB, 2019-06-28]: Goldstandard for Task 3
- tass2013-task4.qrel [3KB, 2019-06-28]: Goldstandard for Task 4
Reports
Along with the submission of experiments, participants were invited to submit a paper to the workshop in order to describe their experiments and discussing the results with the audience in a regular workshop session.
Papers should follow the usual SEPLN template given in the author guidelines page. Reports can be written in Spanish or English. In this case there is no limitation in extension as they will be included in the electronic working notes of the conference.
Submitted papers were reviewed by the program committee.
All reports are included in the Proceedings of the TASS workshop at SEPLN 2013. Actas del XXIX Congreso de la Sociedad Española de Procesamiento de Lenguaje Natural. IV Congreso Español de Informática. 17-20 September 2013, Madrid, Spain. Díaz Esteban, Alberto; Alegría, Iñaki; Villena Román, Julio (eds). ISBN: 978-84-695-8349-4. Online at http://www.congresocedi.es/images/site/actas/ActasSEPLN.pdf.
- TASS 2013 - Workshop on Sentiment Analysis at SEPLN 2013: An overview. Julio Villena-Román, Janine García-Morera
- TASS: A Naive-Bayes strategy for sentiment analysis on Spanish tweets. Pablo Gamallo, Marcos García, Santiago Fernández-Lanza
- Sentiment Analysis of Spanish Tweets Using a Ranking Algorithm and Skipgrams. Javi Fernández, Yoan Gutiérrez, José M. Gómez, Patricio Martínez-Barco, Andrés Montoyo, Rafael Muñoz
- Elhuyar at TASS 2013. Xabier Saralegi Urizar, Iñaki San Vicente Roncal
- Political alignment and emotional expression in Spanish Tweets. David García, Mike Thelwall
- Técnicas basadas en grafos para la categorización de tweets por tema. Héctor Cordobés, Antonio Fernández Anta, Luis Felipe Núñez, Fernando Pérez, Teófilo Redondo, Agustín Santos
- Affective Polarity word discovering by means of Artificial General Intelligence techniques. Rafael del Hoyo, Isabelle Hupont, Francisco Lacueva
- Experiments using varying sizes and machine translated data for sentiment analysis in Twitter. Alexandra Balahur, José M. Perea-Ortega
- LyS at TASS 2013: Analysing Spanish tweets by means of dependency parsing, semantic-oriented lexicons and psychometric word-properties. David Vilares, Miguel A. Alonso, Carlos Gómez-Rodríguez
- SINAI-EMML: Combinación de Recursos Lingüíticos para el Análisis de la Opinión en Twitter. Eugenio Martínez Cámara, Miguel Ángel García Cumbreras, M. Teresa Martín Valdivia, L. Alfonso Ureña López
- LSA based approach to TASS 2013. A. Montejo-Ráez, M. C. Díaz-Galiano, M. García-Vega
- TECNALIA-UNED @ TASS: Uso de un enfoque lingüístico para el análisis de sentimientos. Esther Villar Rodríguez, Ana Isabel Torre Bastida, Ana García Serrano, Marta González Rodríguez
- Are topic classification and sentiment analysis really different? Francisco Javier Rufo Mendo
- UNED LSI @ TASS 2013: Considerations about Textual Representation for IR based Tweet Classification. Ángel Castellanos González, Juan Cigarrán Recuero, Ana García Serrano
- ELiRF-UPV en TASS-2013: Análisis de Sentimientos en Twitter. Ferran Pla, Lluís-F. Hurtado
Registration
Participants were required to register for the task(s). Registration had to be done by mail to tass AT daedalus.es.
The registration is now closed.


