Subtask A: Identification of Key Phrases
Given a list of eHealth documents written in Spanish, the goal of this subtask is to identify all the key phrases per document.
As input a list of documents in plain text is given. Each document is named input_<topic>.txt where topic is a keyword such as “asma”, “cancer”, etc., related to the topic of the document. These topic labels are only used in this subtask to relate input files to output files. A description document for the corpus is provided which explains the source of each of the input files.
An example input file containing plain text is given below. No preprocessing or tokenizing is performed on the text. All inputs are encoded into UTF-8. Each sentence appears on a new line.
The output consists of a list of documents, corresponding to the input files, in the following format: [ auto-increment identifier (ID) , start offset (START) , end offset (END) ]. The files should be named output_A_<topic>.txt , where <topic> matches with the corresponding input file. The A refers to subtask A applied.
Each output document regarding the Subtask A will contain a line per entry. Each entry represents a span of text that has been identified, i.e. a key phrase. Each entry contains three numbers separated by a single whitespace (or tab). The first number indicates an ID , and should be an auto incremented integer that will be used in later subtasks to reference the corresponding text span. The second number is an integer indicating the START of the text span, that is, the zero-based index with respect to the whole document of the first character of the text span. The third number is an integer that indicates the END of the text phrase, that is, the zero-based index with respect to the whole document of the first character after the span. This means that END minus START is equal to the length in characters of the text span.
For example, the following figure shows the annotation of the previous example (as seen in the Brat annotation tool). In this first subtask it is only important to detect the key phrases, i.e., the fragments of the text that are highlighted in light blue.
The following fragment shows the expected gold output for the previous input file, that exactly matches what the sample figure shows. Notice that the first entry is identified with ID=1 and START=3, END=7 . It represents the phrase “asma” seen in the first sentence, which spans from character 3 to character 6 in the document, for a total of 4 characters, hence 7-3=4 . The next entry represents the text “afecta”, and so on. It is not necessary for this file to list all text spans in increasing order of START , although doing some might be convenient for manual inspection and easier debugging.
Please notice that some key phrases can be overlapping, such as the case of “vias” and “vias respiratorias”, or as the case of “ataque de asma” and “asma”. Each of these key phrases should be identified independently.
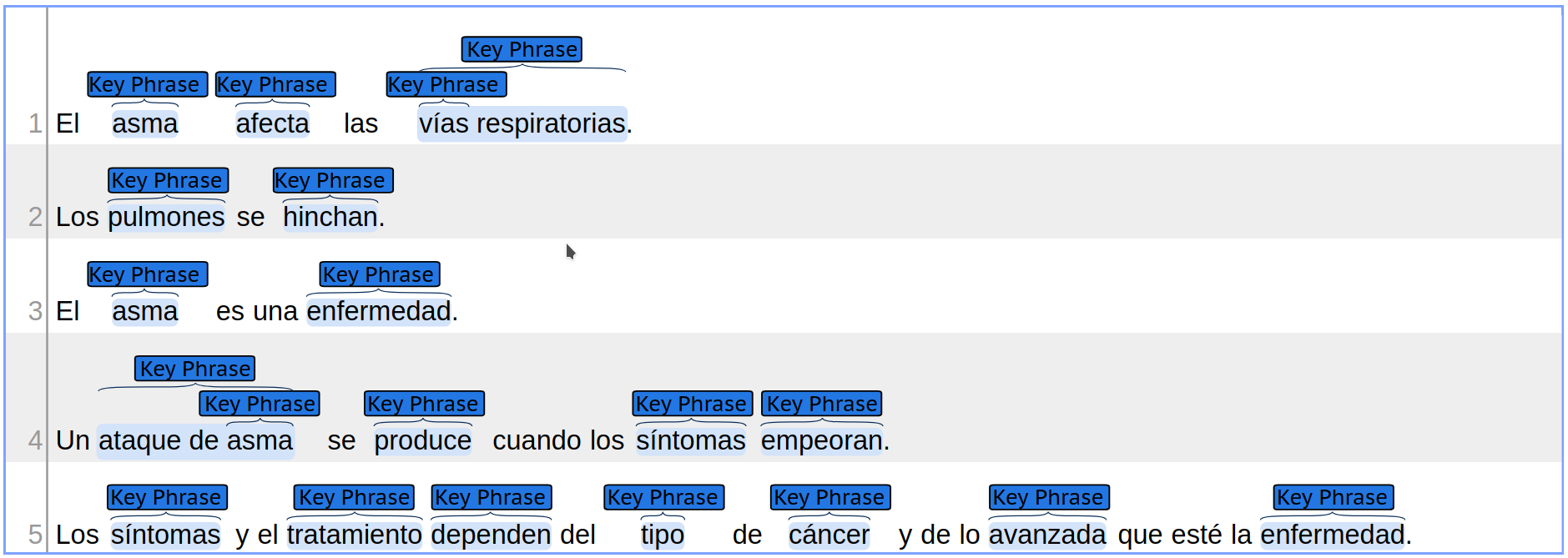
Subtask A gold output example:
- Structured data regarding the key phrases' offsets: file gold/output_A_example.txt
Development evaluation for Subtask A
There are different issues to deal with in terms of evaluation when the dev output files are processed. To illustrate some of them the following fragment shows another possible output simulating a participant team (e.g. teamX), but this time some mistakes have been introduced. There are some entries missing while other entries have been incorrectly added , in contrast to the gold file.
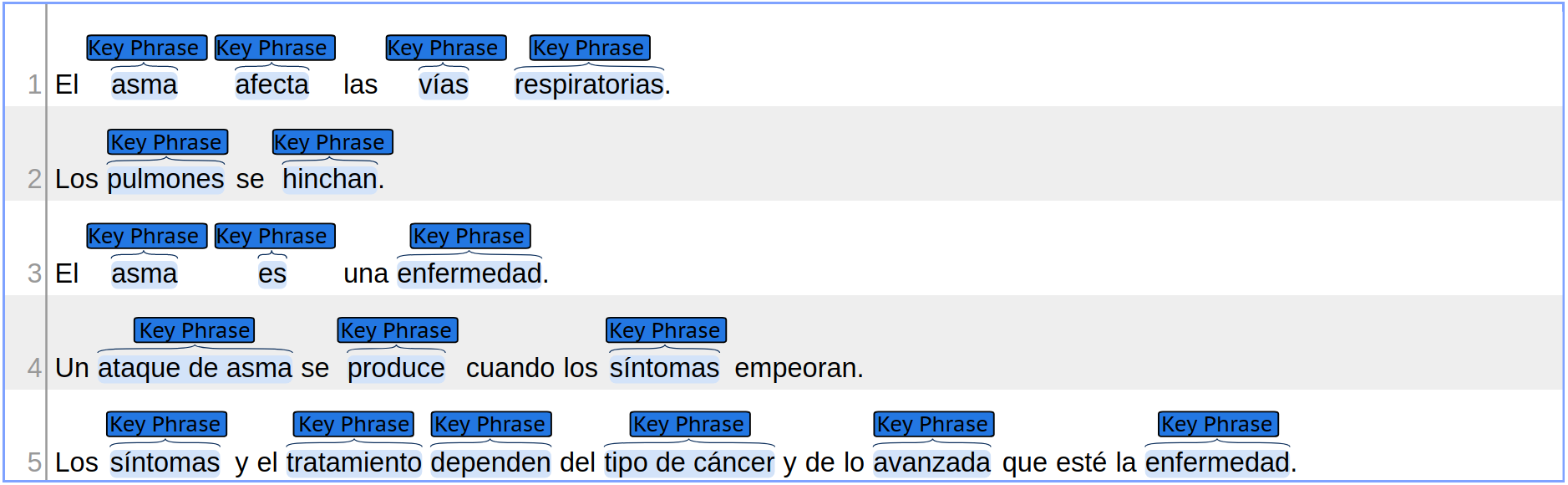
Example dev ouput file:
An evaluation script ( score_training.py ) is provided to help participants to easily detect mistakes. The evaluation script receives an optional argument, the path of the training folder. The training/input folder contains the input files ( input_<topic>.txt ) while the training/gold folder contains and the expected gold output files ( for Subtask A these are the files called output_A_<topic>.txt ), and the training/dev folder contains the output files to be evaluated (for Subtask A these are the files called output_A_<topic>.txt).
An example folder training_example is provided with the previous examples, to illustrate how to use the evaluation script. Running this script using this example folder produces the following result (only showing output that is relevant for the Subtask A):
The evaluation script reports correct , partial , missing and spurious matches. The expected and actual output files do not need to agree on the ID for each phrase, nor on their order. The evaluator matches are based on the START and END values. However, it is important to pay attention to the ID s which will be used in the following Subtasks B and C.
A brief description about the metrics follows:
- Correct matches are reported when a text in the dev file matches exactly with a corresponding text span in the gold file in START and END values. Only one correct match per entry in the gold file can be matched. Hence, duplicated entries will count as Spurious .
- Partial matches are reported when two intervals [START, END] have a non-empty intersection, such as the case of “síntomas” and “los síntomas” in the previous example. Notice that a partial phrase will only be matched against a single correct phrase. For example, “tipo de cáncer” could be a partial match for both “tipo” and “cáncer”, but it is only counted once as a partial match with the word “tipo”. The word “cancer” is counted then as Missing . This aims to discourage a few large text spans that cover most of the document from getting a very high score.
- Missing matches are those that appear in the gold file but not in the dev file.
- Spurious matches are those that appear in the dev file but not in the gold file.
The evaluation script also reports precision , recall , and a standard F1 measure, calculated as follows:
|
NOTE: These metrics are only reported for convenience here, to be used by the participants when developing their solutions. The actual score used for ranking participants will be presented later. |
A higher precision means that the number of spurious identifications is smaller compared to the number of missing identifications, and a higher recall means the opposite. Partial matches are given half the score of correct matches, while missing and spurious identifications are given no score.